Travailler de nos jours sur les différentes plateformes numériques requiert l’utilisation de nombreux formats de fichiers. En effet, manipulés par des applications ou des logiciels, ceux-ci contiennent des données que nous pouvons lire et analyser, ou que nous pouvons être amenés à mettre à jour.
Dans ce premier article d’une série sur les formats de fichiers, nous faisons une revue des formats « texte » que nous rencontrons le plus souvent dans les projets de nos clients, et nous vous montrons comment les manipuler avec Python. Dans les articles suivants, nous verrons le cas des fichiers de données tabulaires, celui des fichiers bureautiques, et pour finir, les autres types de fichiers qu’il est intéressant de savoir manipuler.
Si vous souhaitez utiliser cet article de manière pratique, il est accompagné d’un notebook Jupyter et des fichiers de données des exemples présentés.
Vous retrouverez tous les éléments dans notre dépôt Github ici : https://github.com/ContentGardeningStudio/learning
_text_files_manipulation
Pour en savoir plus sur l’environnement d’exécution interactif Jupiyper et les notebooks, voir : https://jupyter.org/documentation
Le texte simple
Encore appelé fichier texte brut, le fichier texte simple est un document dont le contenu est exclusivement une suite de caractères. Ainsi, pour être précis, nous parlons ici des caractères imprimables, des caractères d’espace et du retour à la ligne.
Le fichier texte utilise nécessairement une forme spécifique de codage des caractères pouvant être une extension du standard des Etats-Unis, l’ASCII.
Ce type de fichier est généralement créé avec l’extension .txt ou .text, mais ce n’est pas obligatoire. Souvent, les ingénieurs ou administrateurs « système » manipulent des fichiers journaux (ou logs), générés par des logiciels sur des serveurs, et ayant des extensions différentes selon le logiciel.
D’ailleurs, pour le programmeur, l’extension n’est pas l’élément important ; votre programme peut avoir en entrée des fichiers générés par un logiciel ou une API, qui ont une extension inhabituelle, voire qui n’ont pas d’extension du tout.
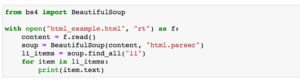
Pour ouvrir un fichier texte existant sur votre machine, en lecture seule, nous utilisons la fonction « open() » en lui passant le chemin du fichier et le mode d’ouverture, ici la valeur ‘rt’ (avec ‘r’ pour Read et ‘t’ pour texte) ; cela retourne un objet représentant le fichier en cours de manipulation, et on peut lire son contenu via la méthode « read() » de cet objet. De plus, l’utilisation de l’élément de syntaxe « with » garantit que le fichier sera fermé après l’opération, donc la mémoire de la machine nettoyée, ce qui est important pour ne pas occuper de la mémoire inutilement.

Pour ouvrir un fichier texte en écriture, ce qui est valable que ce soit pour mettre à jour un fichier existant ou pour le créer, nous utilisons la variante avec la valeur ‘wt’ pour le mode et la méthode « write() » de l’objet représentant le fichier permet de passer la chaîne de caractère à écrire dans le fichier.

Sachez que nous avons également l’indicateur de mode ‘a’ (pour « append »), ce qui donne ‘at’ pour le texte, utile lorsque vous voulez ajouter du texte à la suite de l’existant.
Le HTML
Le format HyperText Markup Language (HTML) est le standard utilisé pour la création de sites web. Il est lu par les navigateurs qui interprètent tout le codage des textes, couleurs, liens hypertexte et autres éléments de formatage. Il permet également, via du code spécifique, l’insertion et la présentation d’images, de documents « audio » ou « vidéo », et plus.
Les fichiers HTML, tels qu’ils sont déployés sur les serveurs web, ont l’extension .html ou .htm.
Souvent, nous traitons du texte au format HTML en le récupérant automatiquement des pages web (techniques de « web scraping »), puis en l’analysant avec un parseur HTML. Dans d’autres cas, nous avons à disposition sur la machine le fichier HTML, et nous l’ouvrons pour traiter son contenu avec le parseur.
Pour manipuler du texte HTML dans le but d’en extraire les données, une technique relativement simple se base sur la bibliothèque tierce-partie de Python, « BeautifulSoup ». Et vous devez l’installer si besoin, en utilisant la commande suivante :
pip install bs4.
Comme vous le voyez à l’aide de notre notebook de démonstration, vous utilisez l’appel « BeautifulSoup(content, « html.parser ») » pour obtenir l’objet qui représente la structure HTML du fichier. Cet objet porte des méthodes telles que « find_all() », qui est très pratique pour trouver, dans le texte, tous les éléments correspondant à une balise donnée.
Le XML
Les échanges de données sont devenus des actions récurrentes dans les processus industriels. Le XML (Extensible Markup Language) a été inventé pour aider à faciliter ce type d’actions. On peut penser aux transferts de données sur les transactions, les produits, les données du personnel au sein des entreprises, ou les informations des marchés financiers.
Le format ou langage XML est basé sur des balises, comme le HTML, mais contrairement à ce dernier, le XML intervient en arrière-plan dans les traitements informatiques ; on parle souvent de « langage machine ».
Les fichiers XML utilisent l’extension .xml.
Pour analyser du XML avec Python, nous pouvons également nous baser sur « BeautifulSoup ». En vous référant au notebook, vous comprendrez rapidement la logique : ici, nous avons pu trouver tous les éléments correspondant à une balise XML donnée en utilisant « find_all() ».

Le JSON
Le JSON (JavaScript Object Notation) est un format de fichier dérivé du langage JavaScript. Comme le XML, le JSON sert aux échanges de données.
Dans un fichier JSON (fichier généralement d’extension « .json »), les données sont stockées de manière organisée, en utilisant des paires « clé / valeur ».
Même si nous en parlons ici, au sein de la catégorie des fichiers texte, le JSON est quand même un cas un peu spécial, dans la mesure où le contenu d’un fichier JSON représente un objet JavaScript (ou un tableau avec plusieurs objets). Étant un outil d’échange de données pour JavaScript, les valeurs stockées au sein du fichier peuvent être un nombre, une chaîne de caractères, null, true ou false, un objet JavaScript ou un tableau.
Pour manipuler du JSON avec Python, pas besoin d’un module tierce-partie. Ainsi, nous pouvons utiliser le module « json » inclus dans Python. La fonction « load() » du module sert à charger en mémoire la structure JSON contenue dans un fichier, à partir du descripteur du fichier obtenu en ouvrant le fichier comme tout fichier texte. Dans cet exemple, on obtient un objet Python, de type Dictionnaire.

Sachant que le dictionnaire est un type d’objet classique et omniprésent dans Python, nous sommes dans notre zone de confort pour exploiter ce résultat.
On peut aussi transformer une structure de données Python en JSON et stocker le résultat dans un fichier, le tout en une action. On parle de « sérialisation ». Pour sérialiser les données en JSON, on utilise la fonction « dump() » du module « json », comme le montre notre dernier exemple, en lui passant le dictionnaire Python et le descripteur du fichier ouvert en écriture.

Vous l’avez compris, comme « BeautifulSoup » pour les fichiers HTML et XML, le module « json » est très pratique pour manipuler du JSON.
Conclusion
Vous avez pu voir comment manipuler un fichier texte simple, le format de base de tout ficher content du texte imprimable.
De plus, pour les formats textuels spécifiques tels que HTML, XML, ou JSON, comme nous l’avons vu, il existe des outils (parseurs) pour manipuler les données de manière efficace. Nous nous sommes volontairement limités à BeautifulSoup pour le HTML / XML et json pour le JSON, mais il existe des solutions alternatives pour lesquelles vous pourriez opter selon votre besoin spécifique et vos contraintes.
Pour d’autres types de fichier texte, si vous devez extraire leurs données de manière précise, vous pourriez trouver le bon parseur en cherchant dans l’écosystème des bibliothèques Python.


