Lorsqu’on explore des données, les tableaux et les statistiques descriptives sont utiles, mais la visualisation permet souvent de mieux comprendre les tendances, les anomalies et les relations entre variables.
Dans cet article, nous allons voir comment utiliser Pandas (et Matplotlib) pour réaliser des visualisations simples et efficaces lors d’une exploration de données.
Nous allons suivre les étapes suivantes :
- Charger les données d’un fichier CSV,
- Explorer graphiquement les distributions,
- Visualiser les relations entre variables,
- Réaliser des regroupements et représentations graphiques,
- Personnaliser et exporter ses graphiques.
Tous les exemples seront basés sur un fichier hypothétique de ventes, au format CSV : ventes.csv.
Comme d’habitude, nous commençons par importer les modules Python dont nous dépendons.
import pandas as pd
import matplotlib.pyplot as plt1. Charger les données du fichier CSV
Comme d’habitude pour ce cas d’usage, vous commencez par charger les données et obtenir un aperçu du contenu du DataFrame Pandas obtenu :
df = pd.read_csv("ventes.csv")
# Aperçu des 5 premières lignes
print(df.head())Vos données sont maintenant prêtes à être explorées.
2. Visualiser la distribution des données
# Histogramme de la distribution des quantités
df['Quantité'].hist(bins=20, figsize=(6,4))
plt.title("Distribution des Quantités vendues")
plt.xlabel("Quantité")
plt.ylabel("Fréquence")
plt.show()📊 Résultat obtenu :
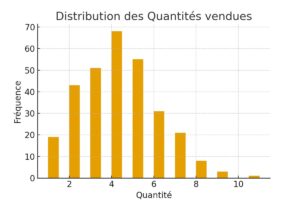
3. Visualiser la relation entre deux variables
# Ajouter une colonne chiffre d'affaires
df['Chiffre_Affaires'] = df['Quantité'] * df['Prix_Unitaire']
# Nuage de points
df.plot(kind='scatter', x='Prix_Unitaire', y='Chiffre_Affaires', alpha=0.6, figsize=(6,4))
plt.title("Relation entre Prix unitaire et Chiffre d'Affaires")
plt.show()📊 Résultat obtenu :
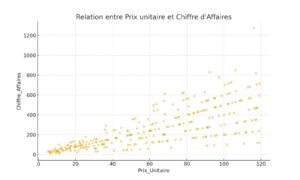
4. Représenter des regroupements (avec groupby)
Pour cet exemple, nous regroupons le chiffre d’affaires par produit dans le dataframe, grâce à la fonction groupby().
# Chiffre d’affaires total par produit
ca_par_produit = df.groupby("Produit")['Chiffre_Affaires'].sum()
# Visualisation
ca_par_produit.plot(kind='bar', figsize=(8,4))
plt.title("Chiffre d'Affaires total par Produit")
plt.ylabel("Montant")
plt.show()📊 Résultat obtenu :
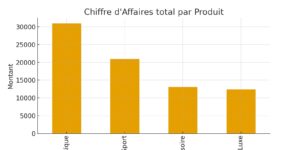
5. Personnaliser et exporter ses graphiques
# Courbe des ventes au fil du temps
ca_par_date = df.groupby("Date")['Chiffre_Affaires'].sum()
ca_par_date.plot(kind='line', marker='o', figsize=(8,4), color="green")
plt.title("Évolution du Chiffre d'Affaires dans le temps")
plt.xlabel("Date")
plt.ylabel("Chiffre d'Affaires")
plt.grid(True)
plt.show()📊 Résultat obtenu :

Conclusion
En combinant Pandas et ses fonctions de visualisation basées sur Matplotlib, il devient facile de passer de simples tableaux de chiffres à des graphiques parlants : histogrammes, nuages de points, barres ou courbes temporelles. Cette étape est essentielle pour détecter les tendances clés et préparer des analyses plus poussées.

